Object(s)ively Awesome
Nutanix Objects?
In August we talked about NUS Files and now it is time to talk about the newest kid on the block (pun intended): Nutanix Objects.
In the Files post we mentioned a study by IDC around the enormous amounts of data that will be created and consumed every day. The same article mentions that roughly 80% of that is expected to be unstructured data.
Guess what is perfect for unstructured data? Object Storage!
S3riously good – it all starts with one standard
While AWS didn’t invent object storage really, it definitely helped make it mainstream.
When S3 was released (2006 or so?), it revolutionized object storage as a concept. Besides the storage server itself, it was the S3 API that was a key differentiator. So much so that competitors and new challengers in the market adopt S3 compatible APIs for their own object storage (that includes Nutanix and the likes of Google, MinIO, etc.).
The S3 API gave developers a universal, programmatic way to store and retrieve data using simple HTTP requests, abstracting away complexity and setting a standard for compatibility across platforms.
Object-Oriented: The Basics of Nutanix Objects
The Object Storage of NUS is another part that is integrated into the overall offering. No other subscription or license is needed, just the used capacity per TiB in NUS and you are good to go.
Just like files, it is based on a couple of service VMs that get created during deployment.

Nutanix Objects architecture with public and storage networks, two Load Balancers, and three Worker Nodes.
We see Load Balancers and Workers. Load Balancers are just that, VMs that balance incoming connections by S3 clients. We want at least two for redundancy purposes per object store. For Workers, unless you do a 1 node deployment, we want 3.
While Load Balancers are a well-known concept, let us focus on the Worker VM. These VMs are small container hosts that run a couple of Microservices, based on Nutanix MSP (https://portal.nutanix.com/page/documents/details?targetId=Objects-v5_1:top-msp-lifecycle-c.html). Internally, microservices are used to implement the S3 API, handle storage communication with the AOS backend, handle object metadata, etc.
(Just like the Fileserver VMs, these are *managed VMs* and do not have to be managed by yourself. They do show up in your infrastructure tab, but you do not need to interact with them.)
As you can see on the screenshot, we have a public network and a storage network. While we generally recommend the object VMs to be on the CVM storage network, you can separate these. Keep in mind more configuration is needed to make sure all necessary ports are available (https://portal.nutanix.com/page/documents/details?targetId=Objects-v5_1:top-network-configurations-r.html).
For the public network, we define an IP range on which the Load Balancer VMs are reachable for clients. This can be your application network, your client network, etc. (do not confuse *public network* with public IPs 😉).
If our number of Load Balancer and Worker VMs are decided and we have configured the necessary firewall rules, we can deploy an Object Store.
Buckets in Store: What is the Object Store?
An Object Store is a “higher level” grouping of object buckets. Every object store deploys its set of VMs (Load Balancers & Workers) and provides its own S3 API endpoint, as well as object namespace. Within an object store is where users create their buckets.

Nutanix Objects management interface showing a list of Object Stores with details such as version, domain, nodes, usage, buckets, objects, notifications, and public IPs
The Object Store level is where we would scale-out the amount of VMs (for more network throughput or scaling storage resources), manage FQDNs and certificates, as well configure advanced features like object federations or Endpoints for notifications and archiving.

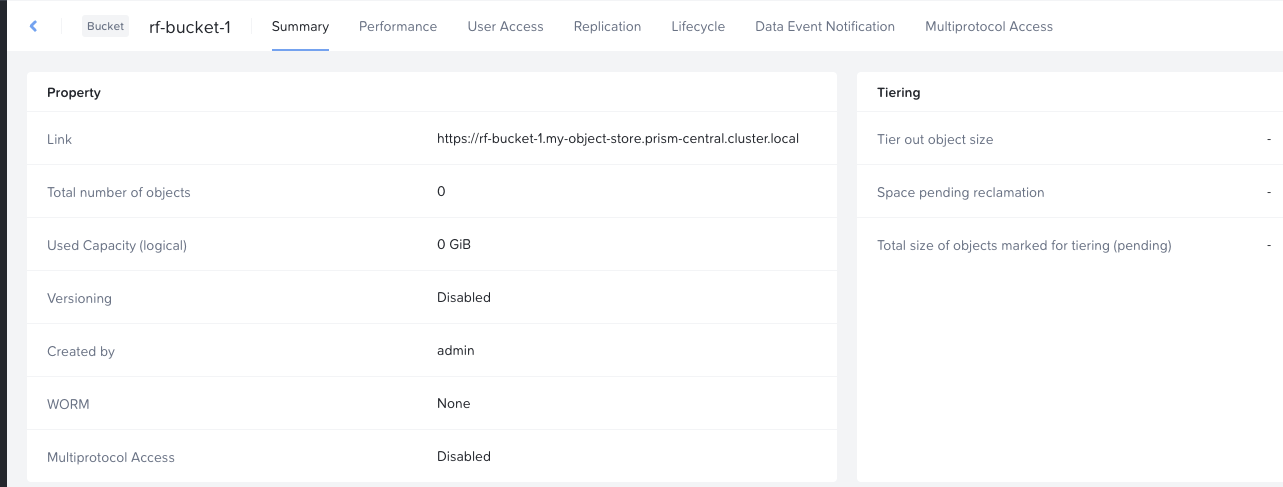
Object Store summary page in Nutanix Objects, displaying configuration details and usage metrics
On that screenshot we see the tab “Buckets” in which we create our object buckets. These buckets have another set of configurable options, like User Access, Replication, etc.
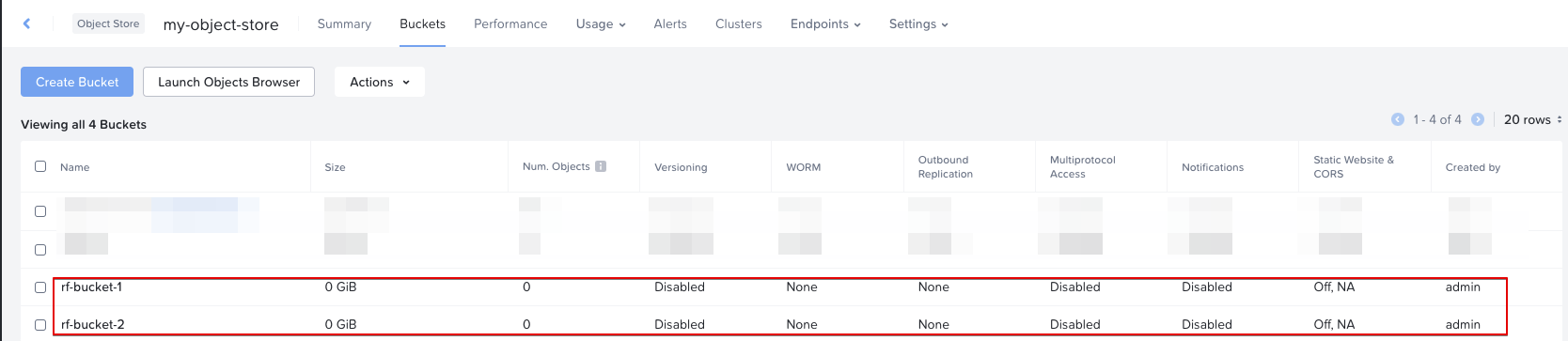
A practical use case for different Object Stores and Object Buckets is tenant abstraction. Each tenant can have their own Object Store. Within their Object Store, they create buckets for various applications, departments, etc.
Abstracting on the Object Store level makes sure that no resources every cross the boundary of a single tenant, including the provisioned VMs.
Data’s Grand Tour: From Requests to Object Buckets
We provisioned an Object Store; we created our buckets – now what?
Now we interact with our S3 API to read and write data, which works as follows:
A client initiates an S3 API request to Nutanix objects (think PUT to write an object or GET to read an object). The API request includes authentication and metadata.
One of the Load Balancers picks up the request and distributes it to one of the Worker VMs (the S3 endpoint microservice really).
The Worker validates the request (request authentication happens here, as well as metadata processing) and executes the GET or PUT operation.
On that same Worker, the next microservice interacts with the AOS layer to retrieve or update the requested object. With that, we also update the metadata of that object.
After that, the Worker prepares the response (e.g. the requested object if the call was GET or a confirmation of a successful write for PUT) and sends that to the Load Balancer.
The Load Balancer forwards the Workers response to the client, completing the communication.

Flow of S3 API requests through Nutanix Objects
Buckets of potential: Real-World Use Cases
After we successfully put an object into a bucket and read from it, why do we care? We had file services for a while, and they do a decent job at handling data.
Scalability beyond believe
File storage works fine until it does not. When you scale to millions and billions of files, traditional file systems reach their limits. Object storage thrives here. With flat namespaces and metadata driven operations, it just keeps going, (almost) regardless of how much data your throw at Nutanix Objects.Metadata is more than a pretty label
File systems have file names, paths, and a timestamp, that is pretty much it. Nutanix Objects lets you add meaningful context to your data by adding key:value style tags to your objects. Objects then become groupable, easier to manage and query. Need to find all objects related to a certain project? No problem, just query for the metadata (e.g. project ID = 1234) and off you go.Cloud-Native or Bust
Modern apps do not want to mess with file paths and hierarchies. Developers want simple APIs and easy accessibility. Object storages power modern, cloud native applications that scale elastically (even across geographies). File systems look like that one friend that still sends letters instead of instant messages.Immutability for peace of mind
Ransomware and compliance don’t pair well with traditional file systems. Object storage offers features like WORM policies (write-once, read-many), making objects tamper-proof after they’re written. This level of immutability makes compliance a breeze and protects data from unauthorized encryption by ransomware at the same time!
Wrapping It Up: Why Nutanix Objects is (Objects)ively Awesome
Object storage isn’t just another way to store data—it’s a game-changer for how we handle modern workloads. Whether you’re managing petabytes of unstructured data, building cloud-native applications, or just looking for a scalable, secure way to keep ransomware at bay, Nutanix Objects has you covered.
From its seamless integration with the Nutanix ecosystem to its scalability, Nutanix Objects proves that it’s not just about storing data—it’s about storing it smarter. Whether you're creating a data lake for analytics, archiving backups, or simply looking for a storage solution that grows with you, Nutanix Objects is ready to take on the challenge. It’s storage, done the modern way.